# 【转】字符串哈希函数
2017-08-24
原文:http://www.cnblogs.com/uvsjoh/archive/2012/03/27/2420120.html 备份在此
# 基本概念
所谓完美哈希函数,就是指没有冲突的哈希函数,即对任意的 key1 != key2 有h(key1) != h(key2)。 设定义域为X,值域为Y, n=|X|,m=|Y|,那么肯定有m>=n,如果对于不同的key1,key2属于X,有h(key1)!=h(key2),那么称h为完美哈希函数,当m=n时,h称为最小完美哈希函数(这个时候就是一一映射了)。
在处理大规模字符串数据时,经常要为每个字符串分配一个整数ID。这就需要一个字符串的哈希函数。怎么样找到一个完美的字符串hash函数呢? 有一些常用的字符串hash函数。像BKDRHash,APHash,DJBHash,JSHash,RSHash,SDBMHash,PJWHash,ELFHash等等。都是比较经典的。
下面是转载的对几个常用字符串hash函数的分析: http://www.cnblogs.com/atlantis13579/archive/2010/02/06/1664792.html
常用的字符串Hash函数还有ELFHash,APHash等等,都是十分简单有效的方法。这些函数使用位运算使得每一个字符都对最后的函数值产生影响。另外还有以MD5和SHA1为代表的杂凑函数,这些函数几乎不可能找到碰撞。
常用字符串哈希函数有 BKDRHash,APHash,DJBHash,JSHash,RSHash,SDBMHash,PJWHash,ELFHash等等。对于以上几种哈希函数,我对其进行了一个小小的评测。
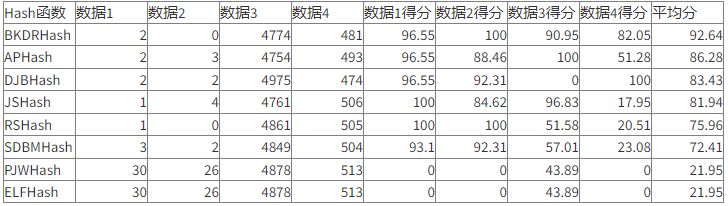
其中数据1为100000个字母和数字组成的随机串哈希冲突个数。数据2为100000个有意义的英文句子哈希冲突个数。数据3为数据1的哈希值与 1000003(大素数)求模后存储到线性表中冲突的个数。数据4为数据1的哈希值与10000019(更大素数)求模后存储到线性表中冲突的个数。
经过比较,得出以上平均得分。平均数为平方平均数。可以发现,BKDRHash无论是在实际效果还是编码实现中,效果都是最突出的。APHash也是较为优秀的算法。DJBHash,JSHash,RSHash与SDBMHash各有千秋。PJWHash与ELFHash效果最差,但得分相似,其算法本质是相似的。
# C代码
unsigned int SDBMHash(char *str)
{
unsigned int hash = 0;
while (*str)
{
// equivalent to: hash = 65599*hash + (*str++);
hash = (*str++) + (hash << 6) + (hash << 16) - hash;
}
return (hash & 0x7FFFFFFF);
}
// RS Hash Function
unsigned int RSHash(char *str)
{
unsigned int b = 378551;
unsigned int a = 63689;
unsigned int hash = 0;
while (*str)
{
hash = hash * a + (*str++);
a *= b;
}
return (hash & 0x7FFFFFFF);
}
// JS Hash Function
unsigned int JSHash(char *str)
{
unsigned int hash = 1315423911;
while (*str)
{
hash ^= ((hash << 5) + (*str++) + (hash >> 2));
}
return (hash & 0x7FFFFFFF);
}
// P. J. Weinberger Hash Function
unsigned int PJWHash(char *str)
{
unsigned int BitsInUnignedInt = (unsigned int)(sizeof(unsigned int) * 8);
unsigned int ThreeQuarters = (unsigned int)((BitsInUnignedInt * 3) / 4);
unsigned int OneEighth = (unsigned int)(BitsInUnignedInt / 8);
unsigned int HighBits = (unsigned int)(0xFFFFFFFF) << (BitsInUnignedInt - OneEighth);
unsigned int hash = 0;
unsigned int test = 0;
while (*str)
{
hash = (hash << OneEighth) + (*str++);
if ((test = hash & HighBits) != 0)
{
hash = ((hash ^ (test >> ThreeQuarters)) & (~HighBits));
}
}
return (hash & 0x7FFFFFFF);
}
// ELF Hash Function
unsigned int ELFHash(char *str)
{
unsigned int hash = 0;
unsigned int x = 0;
while (*str)
{
hash = (hash << 4) + (*str++);
if ((x = hash & 0xF0000000L) != 0)
{
hash ^= (x >> 24);
hash &= ~x;
}
}
return (hash & 0x7FFFFFFF);
}
// BKDR Hash Function
unsigned int BKDRHash(char *str)
{
unsigned int seed = 131; // 31 131 1313 13131 131313 etc..
unsigned int hash = 0;
while (*str)
{
hash = hash * seed + (*str++);
}
return (hash & 0x7FFFFFFF);
}
// DJB Hash Function
unsigned int DJBHash(char *str)
{
unsigned int hash = 5381;
while (*str)
{
hash += (hash << 5) + (*str++);
}
return (hash & 0x7FFFFFFF);
}
// AP Hash Function
unsigned int APHash(char *str)
{
unsigned int hash = 0;
int i;
for (i=0; *str; i++)
{
if ((i & 1) == 0)
{
hash ^= ((hash << 7) ^ (*str++) ^ (hash >> 3));
}
else
{
hash ^= (~((hash << 11) ^ (*str++) ^ (hash >> 5)));
}
}
return (hash & 0x7FFFFFFF);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
# 编程珠玑中的一个hash函数
//用跟元素个数最接近的质数作为散列表的大小
#define NHASH 29989
#define MULT 31
unsigned in hash(char *p)
{
unsigned int h = 0;
for (; *p; p++)
h = MULT *h + *p;
return h % NHASH;
}
2
3
4
5
6
7
8
9
10
11